Kunstmatige intelligentie (in het Engels Artificial Intelligence, of kortweg AI) is tegenwoordig niet meer weg te denken uit onze samenleving. Bijna iedereen heeft weleens gebruik gemaakt van een chatbot-helpdesk, een serie gekeken n.a.v. een aanbeveling door de betreffende streamingdienst of als bestuurder in een auto gezeten die zelfstandig inparkeert. Stuk voor stuk voorbeelden van alledaagse bezigheden waar AI aan ten grondslag ligt. Het gaat hier dus niet om sciencefiction-scenario's waarbij robots heerschappij over de mensheid willen afdwingen zoals in de Terminator-films, maar om technieken die het leven van mensen makkelijker hebben gemaakt. En hoewel er deskundigen zijn die ons waarschuwen voor de gevaren van AI,1,2 moeten we volgens anderen de hype enigszins temperen.3,4
Twee belangrijke kenmerken van AI-systemen zijn autonomie en aanpassingsvermogen.5 Ten eerste betekent het dat een systeem niet expliciet geprogrammeerd hoeft te worden om een karwei te klaren, maar in plaats daarvan zelfstandig functioneert. Ten tweede betekent het dat een systeem zich kan afstemmen op data die het krijgt aangereikt, ongeacht of deze data bevooroordeeld is.
Eén vorm van AI is machinaal leren (machine learning), wat men kan definiëren als “systemen die beter worden in een bepaalde taak naarmate de hoeveelheid ervaring en gegevens toeneemt”.6 Om te beginnen krijgt het systeem als invoer soms wel miljarden datapunten, wat vroeger big data genoemd werd. Dikwijls gaat hier het credo “hoe meer, hoe beter” op. Daarna voert het bewerkingen uit op deze data; bewerkingen die door een computer gedaan worden en voor de mens in sommige gevallen in nevelen gehuld blijven. Deze bewerkingen of computaties die onder de spreekwoordelijke motorkap plaatsvinden, berusten meestal op statistiek. Dit proces wordt ook wel het “trainen van het model” genoemd. (Let op, in dit artikel wordt geen onderscheid gemaakt tussen de termen model, systeem en algoritme.) Tot slot wordt het systeem geconfronteerd met een nieuw datapunt dat het nog nooit is tegengekomen en geeft als uitvoer een bepaalde waarde. Het is aan de mens om iets met deze informatie te doen, bijvoorbeeld beleidsbepaling. Deze abstracte beschrijving van het principe van machinaal leren wordt in de loop van dit artikel verduidelijkt a.d.h.v. een praktijkvoorbeeld met medische data.
Machinaal leren wordt onderverdeeld in drie stromingen: onbegeleid leren (unsupervised learning), begeleid leren (supervised learning) en bekrachtigingsleren (reinforcement learning).6 Het huidige artikel richt zich op een model dat valt onder begeleid leren. In tegenstelling tot onbegeleid leren is bij begeleid leren de data gelabeld. Dit houdt in dat alle relevante eigenschappen van de datapunten die gebruikt worden om het model te trainen bekend zijn bij de programmeur, die een soort alwetende toezichthouder is. Tijdens het trainen van het model wordt de input tegelijkertijd gepresenteerd met de correcte output. Om in een metafoor te spreken: bij het studeren voor een tentamen heb je tijdens het lezen van de vraag direct het correcte antwoord voorhanden. Stel dat we een classificatiesysteem ontwikkelen dat foto's van honden en katten moet categoriseren, dan “weet” het model al tijdens de trainingsfase of het om een hond of een kat gaat. Het is de taak van het systeem om de juiste link te leggen tussen de gegeven input en de gegeven output, zodat de interne werking van het systeem is afgestemd op de data waarmee het getraind wordt.
Een veelvoorkomend probleem bij het trainen van AI-modellen is dat het model té strak wordt afgestemd op de specifieke data waarmee het getraind wordt. Gevolg is dat het model ook leert van ruis in de data. (Ruis is afkomstig van bijvoorbeeld fouten veroorzaakt door de meetapparatuur of van factoren waar we niet in geïnteresseerd zijn maar die wél de data beïnvloeden. Daarom proberen wetenschappers ruis zoveel mogelijk te weren uit hun modellen.) Deze valkuil staat bekend als overfitting.7 Hierdoor kan het model niet meer generaliseren naar nieuwe data. Denk weer aan die metafoor: als je steeds dezelfde oefenvragen maakt, zul je de lesstof niet voldoende beheersen om tentamenvragen te kunnen maken. De tegenhanger van overfitting is underfitting, waarbij het model te zwak wordt afgestemd op de trainingsdata.
Begeleid leren bestaat uit modellen die geschikt zijn voor classificatie enerzijds of regressie anderzijds. Bij regressiemodellen is de output een getal (lengte, temperatuur, etc.), terwijl bij classificatiemodellen de output een klasse of categorie is (geslacht, provincie, etc.). Eén van de classificatiemodellen is het k-naaste-buren-algoritme. Een algoritme is een stappenplan om tot een oplossing te komen, vergelijkbaar met een recept uit een kookboek. Zie figuur 1 voor een overzicht van kunstmatige intelligentie zoals je dat in online bronnen regelmatig zal tegenkomen.8
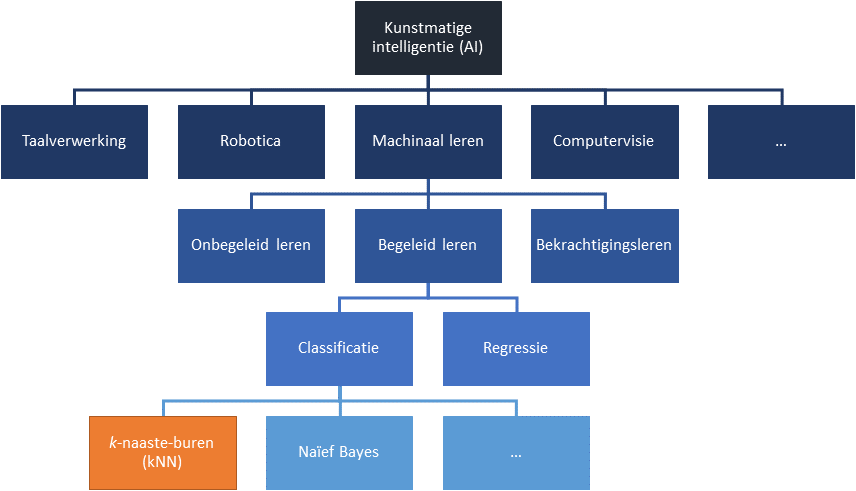
Figuur 1. Het landschap van kunstmatige intelligentie, met hierin k-naaste-buren uitgelicht. Deze grove indeling is allesbehalve volledig. Bovendien zijn er geen strikte afbakeningen tussen disciplines; in werkelijkheid overlappen zij elkaar.
Het k-naaste-buren-algoritme (in het Engels k-nearest neighbors, of kortweg kNN) is eind jaren '60 (her)ontwikkeld door de informatietheoreticus Thomas Cover (1938–2012).9 Het wordt beschouwd als een van de meest eenvoudige AI-modellen. Beeld je een scenario in waarbij je een baan als onderzoeker in een ziekenhuis hebt en wilt voorspellen of iemand lijdt aan dementie, een van de symptomen van de ziekte van Alzheimer. In een database stuit je op geanonimiseerde gegevens van mensen die eerder het ziekenhuis bezocht hebben. Het gaat om hun leeftijd, hersenvolume en diagnose. Door deze variabelen tegen elkaar af te zetten in een puntenwolk, waar ieder punt een individu symboliseert, wordt een beeld van de situatie geschetst (zie figuur 2, bovenste grafiek).
Stel nu dat iemand met klachten van vergeetachtigheid door de huisarts naar de afdeling neurologie wordt doorverwezen. Deze persoon is 66 jaar oud en heeft een hersenvolume van 1860 cm3. Kunnen we op basis van de beschikbare gegevens beoordelen of deze persoon dementie heeft? We kunnen kijken naar een naburig datapunt van iemand met ongeveer dezelfde leeftijd en ongeveer hetzelfde hersenvolume. Dit doen we door een denkbeeldige cirkel met als middelpunt het onbekende datapunt te laten uitdijen. Het aantal punten dat in de cirkel valt noemen we k. Het dichtstbijzijnde datapunt is van een 69-jarige, met een hersenvolume van 1848 cm3, zonder dementie. Omdat slechts één datapunt binnen de cirkel valt, zeggen we dat k = 1. Op basis hiervan zouden we onze potentiële patiënt kunnen classificeren als “geen dementie”. Door de cirkel nog verder uit te breiden totdat er drie datapunten binnen vallen, zien we dat twee van de drie datapunten tot de categorie “dementie” behoren. Dus, bij k = 3 classificeren we onze potentiële patiënt onder de noemer “dementie”. We kunnen de cirkel nog verder uitbreiden tot k = 5, k = 9, enzovoorts. Resumerend: door simpelweg de datapunten in de nabije omgeving te tellen, en de categorie waartoe de meerderheid van deze datapunten behoort te bepalen, maakt het kNN-algoritme een inschatting van de categorie waartoe onze proefpersoon behoort. Het model deelt iets of iemand in op basis van gelijkenis met betrekking tot bepaalde eigenschappen.
Je kunt het kNN-algoritme toepassen op allerlei data waarbij de punten in minimaal twee klassen vallen, en de variabelen kunnen worden uitgedrukt in getallen (statistici zeggen in jargon dat de variabelen van het type “interval” of “ratio” moeten zijn). In de context van kNN wordt een variabele een feature genoemd. Het aantal features kan zelfs meer dan twee zijn, waarvan we later een voorbeeld gaan bekijken. In de puntenwolk is het aantal dimensies gelijk aan het aantal features. Van twee of drie dimensies kunnen we een grafische voorstelling maken, maar bij meer dan drie dimensies wordt het al gauw ingewikkeld.
Andere zaken, zoals de beoordeling of een betaling wel of niet frauduleus is, lenen zich ook voor kNN. Als 95% van de transacties binnen een range van een bedrag (feature 1) binnen een tijdvak (feature 2) frauduleus zijn, kan de bank bij een nieuwe transactie die aan deze criteria voldoet de transactie uit voorzorg blokkeren. Doorgaans wordt de ziekte van Alzheimer vastgesteld d.m.v. neuropsychologisch onderzoek. Kunnen we kNN toepassen om te beoordelen of iemand dementie heeft (en dus een verhoogd risico op de ziekte van Alzheimer)? Zo'n diagnostisch hulpmiddel zou het ziekenhuis een hoop tijd én geld besparen, en daarmee de zorgpremie van burgers drukken. Voor de patiënt kan dit betekenen dat hij/zij het ziekenhuis minder frequent hoeft te bezoeken.

Figuur 2. Een illustratie van het kNN-algoritme in actie voor verschillende k's. Op de x-as staat telkens de leeftijd, op de y-as het hersenvolume, en de diagnose is als rood driehoekje (dementie) of groen rondje (geen dementie) weergegeven.
In de paragraaf “Machinaal leren” is uitgelegd dat een AI-systeem berekeningen uitvoert. Idem voor het kNN-algoritme. Om te bepalen welk(e) datapunt(en) het dichtst bij het te categoriseren punt ligt, moet voor elk datapunt afzonderlijk de afstand tot dit referentiepunt berekend worden. Laten we het onbekende referentiepunt P noemen en het bekende datapunt Q. De kortste afstand tussen twee punten, in dit geval P en Q, is een rechte lijn. Deze afstand heet ook wel de geometrische of Euclidische afstand, vernoemd naar de Griekse wijsgeer en grondlegger van de meetkunde: Euclides.10 Deze lijn vormt de schuine zijde (hypotenusa) van een driehoek, aangevuld met twee rechthoekszijden die P en Q verticaal respectievelijk horizontaal snijden, en samenkomen in punt S (zie figuur 3). Andere benaderingen om de afstand tot het referentiepunt te berekenen zijn o.a. de Manhatten-afstand en de hoekafstand. Deze benaderingen worden in dit artikel buiten beschouwing gelaten. De lengte van de schuine zijde van een rechthoekige driehoek wordt berekend via de stelling van Pythagoras:\[C^2=A^2+B^2\]De lengte van lijnstuk PQ wordt dan:\[{PQ}^2={QS}^2+{PS}^2\]Aan beide kanten van het gelijkheidsteken worteltrekken leidt tot:\[PQ=\sqrt{{QS}^2+{PS}^2}\]Verder weten we dat:\[QS\ =q_x-p_x\]en\[PS\ =p_y-q_y\]Nu hoeven we alleen nog maar QS en PS te vervangen in de aangepaste stelling van Pythagoras. Wat hieruit volgt is:\[PQ=\sqrt{\left(q_x-p_x\right)^2+\left(p_y-q_y\right)^2}\]En omdat het gedeelte tussen haakjes wordt gekwadrateerd, wat altijd zal leiden tot een positief getal, maakt het niet uit of we \(p_x\) van \(q_x\) aftrekken, of andersom. Bijvoorbeeld: \((7-3)^2=(3-7)^2=16\). Of een datapunt links of rechts van het referentiepunt in de grafiek ligt is voor de berekening irrelevant, de uitkomst blijft hetzelfde. We kunnen de formule dus herschrijven naar:\[PQ=\sqrt{(p_x-q_x)^2+(p_y-q_y)^2}\]Uit het voorbeeld in de vorige paragraaf weten we de coördinaten van P (66, 1860) en Q (69, 1848). Deze waardes vullen we in:\[PQ=\sqrt{(66-69)^2+(1860-1848)^2}\approx12,53\]
De afstand tussen punt P en punt Q is ongeveer 12,53 (zie figuur 2, subplot k = 1). Om de formule niet alleen voor lijnstuk PQ te laten gelden, maar voor ieder denkbeeldig lijnstuk, kunnen we meer algemeen zeggen dat:\[afstand(p,q)=\sqrt{(p_x-q_x)^2+(p_y-q_y)^2}\]Misschien valt je een patroon op in deze formule... Wat er tussen haakjes staat aan beide kanten van het plusteken lijkt verdacht veel op elkaar. Momenteel is deze alleen te gebruiken voor het berekenen van de afstand tussen twee punten in twee dimensies (twee features), namelijk x en y. Als laatste stap kunnen we de formule herschrijven zodat deze tevens te gebruiken is voor het berekenen van de afstand tussen twee punten over een willekeurig aantal dimensies:\[afstand(p,q)=\sqrt{\sum_{i=1}^{d}(p_i-q_i)^2}\]De Griekse hoofdletter sigma is in de wiskunde het sommatieteken, d staat voor het aantal dimensies en i is het indexnummer van de dimensies. Kortom, in alle dimensies wordt het verschil tussen punt p en punt q berekend. Voor elke dimensie levert dat een getal op, dat vervolgens wordt gekwadrateerd. Al deze gekwadrateerde getallen worden bij elkaar opgeteld. Tot slot wordt uit deze som de wortel getrokken. Dit maakt het model geschikt voor meerdere input-features.
Het hier beschreven algoritme wordt voor elk van de datapunten t.o.v. het referentiepunt uitgevoerd, wat resulteert in een lijst met afstanden tot het referentiepunt: voor elk datapunt één afstand. Daaropvolgend wordt deze lijst van klein naar groot gesorteerd. Het eerste item uit de lijst ligt het meest dichtbij, het laatste item het meest ver weg. Zo kan het systeem efficiënt bepalen welke datapunten in de nabije omgeving van het referentiepunt liggen. De klassen van de datapunten worden overeenkomstig gesorteerd. Het aantal items in de lijst met afstanden moet identiek worden aan k en wordt daarom afgekapt. (In de afstanden van de overige datapunten zijn we niet geïnteresseerd.) De corresponderende klassen van die datapunten worden bij elkaar opgeteld en de meerderheid “wint”: deze klasse wordt toegekend aan het referentiepunt.
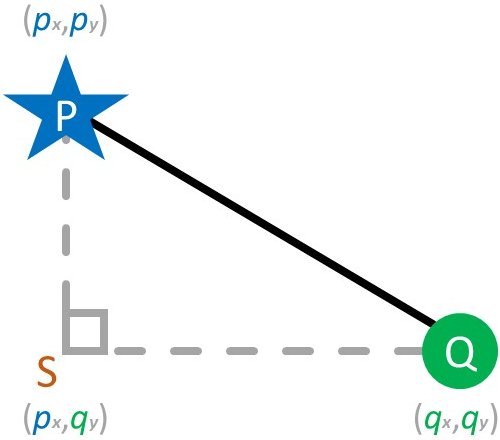
Figuur 3. De driehoek PQS.
Het doel van het systeem is om nieuwe datapunten zo goed mogelijk te classificeren; het moet kunnen generaliseren naar de echte wereld. Maar hoe weet je nou welke waarde voor k de beste voorspelling van de klasse van nieuwe datapunten geeft? Is dat 1, 2, 99, of misschien wel 1.000.000?
Ten eerste moet k kleiner zijn dan het aantal punten in de dataset. Als k even groot is als het aantal punten in de dataset zullen alle toekomstige punten die ingedeeld moeten worden, toegewezen worden aan dezelfde categorie waartoe het merendeel van de punten in de dataset behoort. Meer daarover onder het kopje “Bias-variantie compromis”. Ten tweede komen alle even getallen niet in aanmerking. Hiermee wordt voorkomen dat er een “gelijkspel” tussen twee categorieën kan ontstaan. Stel dat een k van 10 (een even getal) wordt gekozen, en 5 punten behoren tot categorie A en 5 andere punten tot categorie B. Tot welke categorie wordt het te testen punt gerekend? Dit probleem wordt handig omzeild door voor k een oneven getal te kiezen.
Als vuistregel wordt een k gekozen van \(\sqrt N\) waarbij N de steekproefgrootte is.11 In een dataset van negentig deelnemers wordt \(k=\sqrt{90}\approx9\). Dit is een generieke methode om k te vinden en past mogelijk helemaal niet bij onze dataset. Onder het kopje “De dataset” bekijken we een andere methode om de optimale k te vinden, namelijk door een deel van de dataset te gebruiken. Maar wat zijn nou eigenlijk de gevolgen voor het kiezen van een (te) hoge of een (te) lage k?
De zogeheten bias kun je beschouwen als de tendens van het algoritme om een testpunt tot een bepaalde categorie te rekenen. Daarentegen kun je variantie beschouwen als de grilligheid van het algoritme om een testpunt tot een bepaalde categorie te rekenen. Bias en variantie gaan hand-in-hand: hoe hoger de keuze voor k, des te groter wordt de bias en des te kleiner de variantie.7 Het model wordt robuuster en minder gevoelig voor uitbijters (outliers). Een hoge bias correspondeert met underfitting, want het toevoegen van nieuwe trainingsdata zal het model nauwelijks doen veranderen. Het omgekeerde is ook waar: hoe lager de keuze voor k, des te kleiner wordt de bias en des te groter de variantie. Het model wordt minder robuust en gevoeliger voor uitbijters. Een hoge variantie correspondeert met overfitting, want het toevoegen van nieuwe trainingsdata zal het model ingrijpend doen veranderen. Kortom, bias en variantie vormen een “wip-effect” met elkaar. Hier moet een balans in gevonden worden zodat het model correcte voorspellingen kan doen. Je keuze voor k is dus sterk afhankelijk van de vorm van je dataset. Vertoont je data veel spreiding? Misschien is het dan verstandig om een hoge waarde voor k te kiezen. Is je data gegroepeerd in meerdere hechte clusters? Wellicht is een lage k dan een betere optie. Nu we de theorie hebben besproken, kunnen we een interessant voorbeeld uit de praktijk onder de loep nemen waar we het k-naaste-buren-algoritme op gaan toepassen.
De dataverwerking en data-analyse worden verricht in de programmeertaal Python. Door hier te klikken kun je het Jupyter Notebook inclusief de dataset downloaden. De gebruikte dataset is afkomstig van OASIS, een project dat neurologische beeldvormingsdata gratis beschikbaar stelt aan de wetenschappelijke gemeenschap.12
De dataset bestaat uit 150 mensen, waaronder 88 vrouwen en 62 mannen, in de leeftijd van 60 tot 96 jaar. 64 van hen zijn dement, 86 niet (waaronder 14 mensen die bij aanvang van de studie niet dement waren, maar dat tijdens de studie zijn geworden). Ons model gaat gebruikmaken van drie input-features: leeftijd, aantal jaren educatie en hersenvolume. (In de uitleg hierboven hebben al twee dimensies de revue gepasseerd: leeftijd en hersenvolume.) De output-feature is uiteraard de klasse: wel of niet dement. Elk van de 150 individuen in de dataset heeft een waarde op deze vier eigenschappen. Iemand kan bijvoorbeeld 71 jaar oud zijn, 16 jaar gestudeerd hebben (basisonderwijs, voortgezet onderwijs en hoger onderwijs), 1357 cc aan grijze massa bezitten en lijden aan dementie.
Allereerst moet de dataset gesplitst worden in drie (ongelijke) delen. Hoewel de verhoudingen kunnen verschillen per model, hanteren wij 60%-20%-20%. Het eerste deel (dat bestaat uit 3/5e van de dataset) is de trainingset, het tweede deel (1/5e) is de validatieset en het derde deel (1/5e) is de testset. Deelnemers zijn willekeurig toegewezen aan één van deze drie groepen. De trainingset wordt gebruikt om het model te trainen, de validatieset wordt gebruikt om de beste waarde voor k te kiezen, en de testset wordt gebruikt om te controleren hoe het systeem in de realiteit zou presteren.
Alvorens het kNN-algoritme te laten draaien, moet de data gemanipuleerd worden. De features leeftijd, educatie en hersenvolume opereren op verschillende schalen. Leeftijd en educatie loopt in de tientallen, terwijl hersenvolume in de duizendtallen loopt. Die schaal moet rechtgetrokken worden zodat alle features evenveel belang bijdragen aan de afstand van een referentiepunt tot een datapunt. Dit doen we door van alle waardes Z-scores te maken en heet “normaliseren”. Het is een basale statistische correctie die buiten het bereik van dit verhaal valt. Als we de data niet zouden normaliseren zou een feature zoals hersenvolume een veel grotere impact hebben op de afstand dan de features leeftijd en educatie.
Laten we aannemen dat punt P, zoals zojuist beschreven, de coördinaten (71, 16, 1357) heeft. Punt Q heeft de coördinaten (71, 2, 1400). En punt R heeft de coördinaten (71, 17, 1410). De leeftijd is bij alle drie hetzelfde (71) en kunnen we voor de berekening van de afstanden negeren. De afstand PQ is ruim 45. De afstand PR is 53. Je zou kunnen concluderen dat Q dichterbij P ligt dan R. Echter, een stapje van 1 op de schaal educatie is relatief gezien vele malen groter dan een stapje van 1 op de schaal hersenvolume. Anders gezegd, hersenvolume levert een grotere bijdrage aan de afstand dan educatie. Op de schaal educatie ligt de waarde 2 bijna vijf standaarddeviaties verwijderd van de waarde 17, terwijl op de schaal hersenvolume de waarde 1410 nog geen halve standaarddeviatie verwijderd ligt van de waarde 1357. (De standaarddeviatie is een maat voor de spreiding van een variabele.) Dat is de reden voor de correctie, waarna de features in Z-scores zullen worden uitgedrukt. Na het opnieuw berekenen van de afstand op de gecorrigeerde schalen zal blijken dat R dichterbij P ligt dan Q. Nu wegen alle features even zwaar en kan het algoritme van start gaan. Overigens kan het in sommige gevallen een bewuste keuze van de programmeur zijn om de ene feature zwaarder mee te laten wegen dan de andere.
De trainingset bestaat uit 90 personen (zie figuur 4). Uit visuele inspectie van de grafiek kunnen we nog geen stellingen afleiden. De datapunten in de trainingset fungeren als referentiepunten. Hier wordt ons model uiteindelijk op afgestemd, vandaar het woord “training”. Een kenmerk van het k-naaste-buren-algoritme is dat het een “lui” algoritme is: voor iedere nieuwe voorspelling worden alle datapunten uit de trainingset geraadpleegd. Bij andere technieken van begeleid leren, zoals lineaire regressie, rolt er na de trainingsfase een formule met coëfficiënten uit de black-box, die gebruikt kan worden voor de berekening van nieuwe datapunten. De trainingset is vanaf dat moment overbodig. Dat is bij het kNN-algoritme niet het geval. Nadeel hiervan is dat het algoritme computationeel intensief is. Met andere woorden, bij datasets met meer punten zal het langer duren voordat het programma is afgerond. In de kleine dataset die wij gebruiken speelt deze factor geen rol van betekenis.
Het is belangrijk dat de trainingset groot genoeg is, aangezien dit de betrouwbaarheid van onze voorspellingen ten goede komt. Als je bijvoorbeeld de gemiddelde lengte van de Nederlandse bevolking wilt schatten op basis van een steekproef, dan is het zinvol om een zo groot mogelijke steekproef te selecteren, zodat deze groep representatief is voor de totale bevolking en de kans op toevallige afwijkingen beperkt wordt. Datzelfde principe geldt voor het selecteren van een trainingset uit de oorspronkelijke dataset. Een alternatief voor bovenstaande verhoudingen is bijvoorbeeld 70%-15%-15%. Bij hele grote datasets met miljarden datapunten kan zelfs gekozen worden voor 80%-10%-10% of 90%-5%-5%. Dit verhoogt de betrouwbaarheid, alhoewel de keerzijde van een grotere fractie aan trainingset is, dat de fracties aan validatieset en testset kleiner zijn, wat afbreuk doet aan de mate van generaliseerbaarheid naar nieuwe datapunten. De onderzoeker staat hierin wederom voor een moeilijke keuze die zijn weerslag kan hebben op de resultaten van het model.

Figuur 4. Een 3D-animatie van de trainingset. Als de y-as (Educatie) loodrecht op het perspectief van de kijker staat, is de grafiek uit figuur 2 te herkennen.
De validatieset bestaat uit 30 personen. De validatieset wordt gebruikt om de optimale parameters voor het model te vinden. Parameters zijn alle variabele eigenschappen die invloed hebben op de prestaties van het model. Oftewel, de spreekwoordelijke “knoppen” waar de onderzoeker aan kan draaien om het model te finetunen. In deze situatie wil dat zeggen dat we met behulp van de validatieset de optimale k proberen te vinden. Er wordt begonnen met k = 1. De datapunten in de validatieset worden één voor één afgezet tegen de datapunten in de trainingset, en op basis daarvan ingedeeld in een bepaalde categorie. Nadat alle datapunten in de validatieset zijn gecategoriseerd (ten opzichte van het dichtstbijzijnde punt uit de trainingset, want k is immers gelijk aan één), wordt de accuratesse (synoniem voor nauwkeurigheid) berekend. Dit percentage wordt tijdelijk opgeslagen. Vervolgens wordt bovenstaande cyclus herhaald voor k = 3, daarna voor k = 5, etc., totdat we voor iedere k een bepaalde score hebben (zie figuur 5). Tot slot wordt de k met de hoogste accuratesse gekozen voor het gebruik in de testset. Dat blijkt k = 41 te zijn, met een accuratesse van 67%. Dit houdt in dat 20 van de 30 mensen uit de validatieset een juiste diagnose (wel/geen dementie) hebben gekregen.
(Disclaimer: bij het kiezen van de k met de hoogste accuratesse is enigszins gefoeteld. Het willekeurig indelen van de deelnemers in de trainingset, validatieset en testset werd net zolang herhaald totdat de beste k een acceptabele score voortbracht. Bij een andere indeling van de deelnemers over de groepen zou het model drastisch verslechteren. Dit is een laakbare werkwijze! Omdat het hier gaat om een educatief verslag en niet om een wetenschappelijke verhandeling, zien we deze miskleun door de vingers.)

Figuur 5. De accuratesse van het model in de validatieset voor verschillende k's. Er lijkt een licht stijgende trend in de lijn waarneembaar.
De testset bestaat uit 30 personen, net zoals de validatieset, en velt een salomonsoordeel over het model. Het programma werd tijdens de validatie voor iedere k doorlopen, tijdens de finale test wordt het programma slechts eenmaal doorlopen, voor k = 41 welteverstaan. Voor ieder punt uit de testset wordt de klasse van die persoon (wel/geen dementie) voorspeld op basis van de klassen van de 41 meest nabije punten. Ook hier is het resultaat een bepaalde score, die in de volgende paragraaf wordt onthuld.
De testset wordt dus pas in de laatste fase van ons experiment gebruikt. Tot die tijd heeft het model nooit inzicht gehad in deze data. Het wordt daarom ook wel het out-sample genoemd. Hiermee voorkom je dat het model wordt afgestemd op de data die je gebruikt om de prestaties van het model te beoordelen. Dit wordt data leakage (datalekkage) genoemd en zou een rooskleuriger beeld van de resultaten schetsen dan zij in werkelijkheid zijn. Het is, naast overfitting, een veelgemaakte fout bij het ontwikkelen van modellen omdat het vaak lastig is vast te stellen. Een voorbeeld is de ontwikkeling van een beleggingsstrategie waarbij de aandelenkoersen van morgen (die je natuurlijk nog niet weet) al worden gebruikt. Of, wederom metaforisch, het model spiekt op het antwoordenblad tijdens het maken van een examen. Dit zou het model van alle objectiviteit ontdoen en gaat ten koste van de validiteit.
Het moment waarop we al die tijd gewacht hebben is aangebroken, een antwoord op de vraag: “hoe goed is ons model?” Tabel 1 toont de indeling van de datapunten uit de testset volgens het model (Voorspeld) en de realiteit (Werkelijk):
| Voorspeld | ||||
| Dementie | Geen dementie | Totaal | ||
| Werkelijk | Dementie | 7 | 6 | 13 |
| Geen dementie | 3 | 14 | 17 | |
| Totaal | 10 | 20 | 30 | |
| Tabel 1. Error-matrix van de testset. | ||||
Hoewel er meerdere criteria bestaan waaraan de prestaties van een kNN-model valt af te meten, bijvoorbeeld de F1-score of Cohen's kappa, dat de betrouwbaarheid tussen beoordelaars meet (waar in deze context de ene beoordelaar de voorspellingen van het model zijn en de andere beoordelaar de werkelijke waarden zijn), wordt hier gekozen voor accuratesse, sensitiviteit en specificiteit.13 Deze drie methodes worden veelvuldig gebruikt in de diagnostiek om de sterkte van een toetsingsinstrument te kwantificeren. Bijkomend voordeel is dat ze makkelijk te berekenen zijn.
De accuratesse (nauwkeurigheid) is de verhouding tussen het aantal correct geclassificeerde punten en het totaal aantal geclassificeerde punten, en wordt uitgedrukt als percentage:\[accuratesse=\frac{aantal\ correct\ geclassificeerde\ punten}{totaal\ aantal\ geclassificeerde\ punten}\times100\%\]Uit tabel 1 is af te lezen dat 7 van de 30 mensen die aan dementie lijden door het model als zodanig zijn ingedeeld. 14 van de 30 mensen die niet aan dementie lijden krijgen volgens het model ook niet dat stempel. Derhalve zijn deze datapunten correct geclassificeerd, waardoor die mensen een gepaste diagnose zouden krijgen indien we het model de diagnose laten stellen in plaats van de medici. Als de getallen worden ingevoerd in de formule hierboven krijgen we:\[(\frac{7}{30}+\frac{14}{30})\times100\%=\frac{21}{30}\times100\%=70\%\]De accuratesse van ons model is 70%! Dit is geen grandioze score, doch beduidend beter dan het opwerpen van een muntstuk. Het model heeft wel degelijk predictieve waarde, maar onderpresteert ten opzichte van varianten van kNN-algoritmes die beoordeeld zijn op datasets met meer features en meer datapunten.14 Opvallend is dat de accuratesse in de testset hoger is dan die in de validatieset (67%). Dit is uitzonderlijk, aangezien het model nog nooit was blootgesteld aan de datapunten uit de testset, maar meermaals kennis heeft genomen van de datapunten uit de validatieset (éénmaal voor iedere k), waaruit de optimale k voortvloeide. Denk tot vervelens toe weer aan die metafoor: je haalt een hoger cijfer voor het tentamen dan voor het oefententamen.
Nadeel van deze meting is dat de accuratesse geen onderscheid maakt tussen de twee groepen, “wel dementie” of “geen dementie”. Het zou in theorie zo kunnen zijn dat het model impliciet een voorkeur voor een klasse heeft, bijvoorbeeld voor “wel dementie”. Gevolg is dat alle mensen met dementie correct worden geclassificeerd, maar ook een buitenproportioneel deel van de mensen zonder dementie (ten onrechte) tot die groep worden gerekend. Een extreem voorbeeld: stel dat een zeldzame ziekte een prevalentie van 0,01% heeft. Dan zou een model dat altijd “niet ziek” voorspelt een accuratesse hebben van 99,99% als de volledige bevolking getest wordt, terwijl het de ziekte nooit zou detecteren. Kortom, accuratesse is geen deugdelijke graadmeter voor de prestatie van het model. Zodoende kijken we naar de sensitiviteit en de specificiteit.
De sensitiviteit is de kans op een “positief” testresultaat, gegeven dat de patiënt daadwerkelijk leidt aan dementie. Positief betekent in dit geval “dementie”. Het wordt ook wel de true positive rate, trefkans, recall of power genoemd. (Het aantal synoniemen geeft aan hoe belangrijk deze maat voor een toetsingsinstrument is. Je wilt er tenslotte voor zorgen dat een toetsingsinstrument mensen die ziek zijn eruit kan pikken.) Zij wordt als volgt berekend:\[sensitiviteit=\frac{aantal\ correct\ geclassificeerde\ positieve\ punten}{totaal\ aantal\ werkelijk\ positieve\ punten}\times100\%\]Er zijn 13 mensen die daadwerkelijk lijden aan dementie (de cel rechtsboven in Tabel 1). Het model heeft 7 van hen geclassificeerd in de categorie “dementie” (de cel linksboven). Hieruit volgt:\[\frac{7}{13}\times100\%\approx54\%\]Ergo, iets meer dan de helft van de mensen die lijden aan de ziekte worden als zodanig geclassificeerd. We kunnen concluderen dat het model een beroerde voorspeller is voor het bevestigen van dementie. Desalniettemin is deze score niet zo rampzalig als die van de test in ons gedachte-experiment, die altijd “niet ziek” als uitslag gaf, waar de sensitiviteit 0% is.
De specificiteit is de kans op een “negatief” testresultaat, gegeven dat de patiënt daadwerkelijk niet leidt aan dementie. Negatief betekent in dit geval “geen dementie”. Het wordt ook wel de true negative rate genoemd. Zij wordt als volgt berekend:\[specificiteit=\frac{aantal\ correct\ geclassificeerde\ negatieve\ punten}{totaal\ aantal\ werkelijk\ negatieve\ punten}\times100\%\]Er zijn 17 mensen die daadwerkelijk niet lijden aan dementie (de cel rechtsmidden in Tabel 1). Het model heeft 14 van hen geclassificeerd in de categorie “geen dementie” (de middelste cel). Hieruit volgt:\[\frac{14}{17}\times100\%\approx82\%\]Ruim vier van de vijf mensen die niet lijden aan de ziekte worden als zodanig geclassificeerd. We kunnen concluderen dat het model een redelijke voorspeller is voor het uitsluiten van dementie.
Ter afsluiting van dit hoofdstuk zou men vanuit een moreel standpunt kunnen betogen dat de sensitiviteit een crucialer facet is dan de specificiteit, omdat we meer belang hechten aan het detecteren van een ziekte dan het uitsluiten ervan. Immers, welk verhaal is hartverscheurender: dat van iemand die ten onrechte te horen krijgt dat hij/zij geen ziekte heeft en deze achteraf wél blijkt te hebben, of dat van iemand die ten onrechte te horen krijgt dat hij/zij een ziekte heeft en deze achteraf niet blijkt te hebben? In het eerste scenario kunnen de consequenties levensbedreigend zijn, het tweede kan uitdraaien op een meevaller en jaren van plezier.
1. Bostrom, N. (2014). Superintelligence – Paths, Dangers, Strategies. United Kingdom: Oxford University Press.
2. CNN. (3 mei 2023). 'Godfather of AI' warns that AI may figure out how to kill people [Video]. YouTube. https://www.youtube.com/watch?v=FAbsoxQtUwM
3. Mitchell, M. (2019). Artificial Intelligence – A Guide for Thinking Humans. New York: Picador.
4. Sabine Hossenfelder. (7 jan 2025). Will We Get AGI In 2025? [Video]. YouTube. https://www.youtube.com/watch?v=pz9FQ1gwh3g
5. University of Helsinki & MinnaLearn. (Aangeroepen op 12 april 2025). Elements of AI. https://course.elementsofai.com/nl/1/1
6. University of Helsinki & MinnaLearn. (Aangeroepen op 12 april 2025). Elements of AI. https://course.elementsofai.com/nl/1/2
7. Grus, J. (2015). Data Science from Scratch. Sebastopol, CA: O'Reilly Media, Inc.
8. Garanhel, M. (2023, mrt 22). What are the top 7 branches of artificial intelligence? AI Accelerator Institute. https://www.aiacceleratorinstitute.com/what-are-the-top-7-branches-of-artificial-intelligence/
9. Wikipedia, The Free Encyclopedia. (2025, March 14). k-nearest neighbors algorithm. https://en.wikipedia.org/wiki/K-nearest_neighbors_algorithm
10. Wikipedia, The Free Encyclopedia. (2025, April 8). Euclidean geometry. https://en.wikipedia.org/wiki/Euclidean_geometry
11. Doolan, T. & Vrielink, W. (2024). Introduction to Machine Learning. Universiteit van Amsterdam (UvA). https://www.uva.nl/shared-content/programmas/en/professionals/introduction-to-machine-learning/introduction-to-machine-learning.html
12. Marcus, D.S., Fotenos, A.F., Csernansky, J.G., Morris, J.C., & Buckner, R.L. (2010). Open Access Series of Imaging Studies (OASIS): Longitudinal MRI Data in Nondemented and Demented Older Adults. Journal of Cognitive Neuroscience, 22, 2677-2684. doi: 10.1162/jocn.2009.21407
13. Spiegelhalter, D. (2020). The Art of Statistics – Learning from Data. UK: Pelican Books.
14. Uddin, S., Haque, I., Lu, H., Ali Moni, M., & Gide, E. (2022). Comparative performance analysis of K-nearest neighbour (KNN) algorithm and its different variants for disease prediction. Scientific Reports, 12(6256). DOI: https://doi.org/10.1038/s41598-022-10358-x